Last Updated on December 16, 2024 by Deepanshu Sharma

While some data is as simple as a spreadsheet, other types are as sensitive and valuable as a secret recipe. This is where data classification steps in. It guides businesses through the subtle lesson of which types of data need protection and how tightly the door of the vault should be shut. But how does one determine the data that requires a password and other data that can be left open for any individual to access? Let’s discuss what role data classification plays in today’s businesses and why it matters so much.
What is Data Classification?
Data classification is the process of categorizing data based on its confidentiality to determine the level of access that should be granted to it and the level of protection it requires against unauthorized access or disclosure. The classification of data can be based on factors such as the type of data, its value, the level of risk of its exposure, and any applicable regulatory requirements. The purpose of data classification is to provide a framework for data management and security that enables organizations to identify and protect their most valuable and sensitive data assets.
Data Classification Reasons and Benefits
There are many reasons/benefits why organizations choose to classify their data, which are as follows:
- Data classification helps ensure sensitive information is properly protected
- It allows organizations to prioritize resources based on the value of the data
- Data classification can help with regulatory compliance by making it easier to respond to subject access requests (SARs)
- It enables more effective data sharing and collaboration within an organization
- Proper data classification can reduce the risk of data breaches or leaks
- It can aid in disaster recovery and business continuity planning
- Classification can help organizations determine appropriate levels of access and control for different types of data
- Classification allows for better data management and organization
- It can support more accurate reporting and analysis of data
- Data classification can help organizations save time and resources by focusing efforts on the most important data.
Types of Data Classification
When we talk about data classification, it simply means that the data is being grouped according to the levels of risks and the security it requires. Here’s a breakdown of the main types of data classification:
- Content-Based Classification: This approach entails taking a look at the user’s data, for instance, documents, spreadsheets, and files in general, and then sorting the data based on its content. For instance, a document that includes lots of data on financial performance will be classified as sensitive, whereas a general memo may not be.
- User-Based Classification: In some cases, the individual who generates or retrieves the data selects the sensitivity level of the records. This means that depending on the user’s role in the organization, this user can define how sensitive some data is or how it should be classified.
- Context-Based Classification: This looks into the environment surrounding the data collected. It could include things such as storage location (cloud or on-premises), data creation time, or even the users and their intended use for the data. This provides an additional layer of complexity in distinguishing between what can be considered sensitive data.
Methods of Data Classification
Now, let’s talk about how organizations classify their data. It’s not about simply putting a ‘Confidential’ label on something and then boasting that it has been done. Data can be classified in several ways depending on what the individuals or organizations require, the tools they employ in the process, or their intended objectives. Here are a few methods commonly used:
- Manual Classification: The most straightforward one, however, the process might be time-consuming when used as the only approach. Users or administrators read through data and sort it according to predefined categories and subcategories. Although this method may yield very accurate results, it is time-consuming and may contain human errors if poorly handled. It is often more beneficial for smaller organizations or if less data is extracted more frequently.
- Automated Classification: This is a method that allows the data to be classified mechanically through the use of software or a tool with particular regulations. These tools work by ‘reading’ files, databases, or documents and converting them to a format where patterns or predefined keywords can be looked for within the search files (for example credit card numbers or medical terms). Automated systems are way better than manual systems as far as speed and scalability of results are concerned but the results largely depend on the settings done for classification.
- Rule-Based Classification: In this method of classification, the classification is by the use of a certain set of rules. These rules can stem from compliance regulations (like GDPR or HIPAA), or they can be internal rules. For instance, if the document has PII that is in any way accessible to the users, the document will default to sensitive or confidential. This method can be made to work in an automated manner and, at the same time, the level of accuracy can be very high.
- Machine Learning-Based Classification: One of the recent enhancements in data classification techniques, machine learning (ML) involves learning from previous classification decisions as well as patterns. With time, the system is able to identify more subtle forms of data as well as the detail, including data that may be construed as sensitive and that was not part of the rules in the first place. This is particularly useful with big data where a human or a set of rules cannot cope with processing such large amounts of data.
- Hybrid Classification: Some organizations use a mix of manual, automated, and machine learning-based methods to create a classification system that suits their specific needs. This hybrid approach can combine the best of both worlds, taking advantage of automation while still maintaining oversight and control of the process.
Data Classification Levels
Data classification involves assigning levels of classification to data based on its sensitivity and confidentiality. These levels help determine the appropriate handling, storage, and access controls for the data. Here are the different levels of data classification commonly used:
- Unclassified: This is the lowest level of data classification. Unclassified data contains information that is non-sensitive and can be freely shared or accessed without any restrictions. It does not pose any risk if disclosed or accessed by unauthorized individuals.
- Confidential: The confidential level is used for data that requires protection due to its sensitive nature. It includes information that, if disclosed or accessed without authorization, could harm individuals or organizations. Access to confidential data is restricted to authorized personnel who have a legitimate need to know.
- Secret: Secret data classification is used for highly sensitive information that, if compromised, could cause significant damage to national security or an organization’s operations. Access to secret data is strictly controlled, and only individuals with appropriate security clearance and a need-to-know basis can access it.
- Top Secret: This is the highest level of data classification. Top secret data contains information that, if disclosed, could cause severe damage to national security or critical infrastructure. It is heavily protected and access is limited to a select few individuals with the highest security clearances.
- Special Categories: In some cases, additional special categories may be defined to address specific types of sensitive data. These categories could include sensitive personal information, financial data, health records, or legal information. Each special category may have its own set of access controls and protection requirements.
Data classification levels ensure that data is handled and protected according to its sensitivity. Organizations and governments define their specific classification levels and associated security protocols based on their unique requirements and the nature of the data they handle. Implementing appropriate data classification helps safeguard sensitive information and maintain data integrity and confidentiality.
Data Classification Examples
Here are some examples of data classification:
- Personal Identifiable Information (PII): This classification includes data that can identify an individual, such as names, addresses, social security numbers, or phone numbers. It is classified as sensitive and requires strict protection to prevent identity theft or privacy breaches.
- Financial Data: Financial data classification encompasses information related to financial transactions, banking details, credit card information, or income records. It requires a high level of confidentiality and security to prevent financial fraud or unauthorized access.
- Medical Records: Medical data classification involves healthcare-related information, including patient medical history, diagnoses, treatment plans, or test results. It falls under strict privacy regulations, such as the Health Insurance Portability and Accountability Act (HIPAA), and requires strong safeguards to protect patient privacy.
- Intellectual Property: This classification includes trade secrets, patents, copyrights, or proprietary information that belongs to a company or individual. Intellectual property data requires stringent protection to maintain its competitive advantage and prevent unauthorized use or theft.
- Government Classified Information: Government data classification involves sensitive information related to national security, defense, or intelligence. It includes classified documents, plans, or strategic information that must be protected from unauthorized disclosure to maintain the integrity and security of the nation.
These are just a few examples of data classification categories. Organizations and industries may have their specific classifications based on their unique needs and compliance requirements. Data classification ensures that appropriate security measures and access controls are implemented based on the sensitivity and confidentiality of the data.
Data Classification Process
The process of data classification will vary based on the organization’s objectives, but certain common practices can lead to successful outcomes. Below are some best practices to consider:
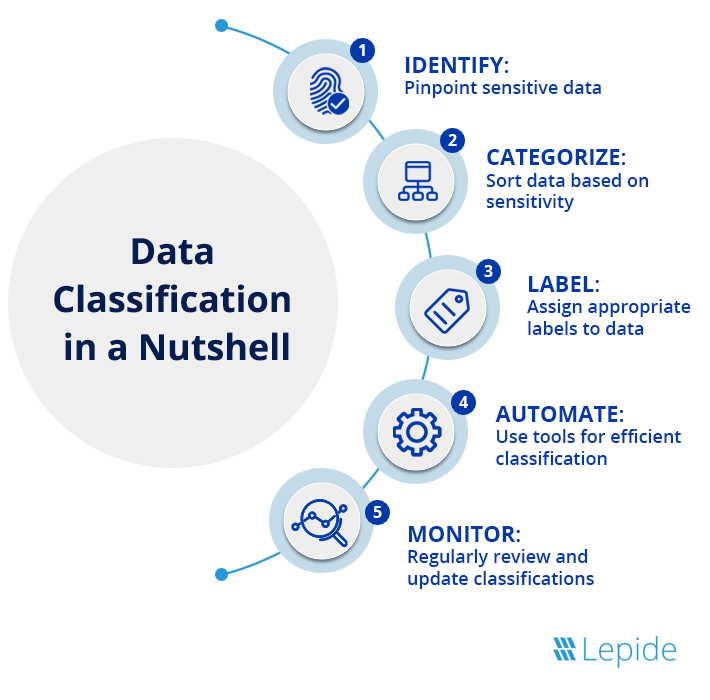
1. Define the objectives of the data classification process
- Identify the in-scope systems for the initial classification phase
- Determine the applicable compliance regulations
- Consider other business objectives such as risk mitigation, storage optimization, and analytics.
2. Categorize data types
- Identify data created/collected by your organization
- Distinguish proprietary data from public data
- Identify all regulated data, such as that covered by GDPR, HIPAA or CCPA.
3. Establish classification levels
- Determine the number of classification levels needed
- Document each level and provide examples (use a classification matrix)
- Train users to classify data if manual classification is required.
4. Define the automated classification process
- Define the prioritization criteria for discovering sensitive data
- Establish the frequency of classification, and resources required to automate the process.
5. Define categories and classification criteria
- Establish high-level categories and provide examples
- Define or enable applicable classification patterns and labels
- Establish a process for validating both user-classified and automated results.
6. Define outcomes and usage of classified data
- Document risk mitigation steps and automated policies
- Determine analysis processes for classification results
- Establish expected outcomes from analytics.
7. Monitor and maintain your classification process
- Develop a workflow to classify new or updated data
- Review and update the classification process if necessary due to changes in business or regulatory requirements.
How Lepide Helps with Data Classification
As data breaches continue to make the headlines, and Governments across the globe implement their own data privacy laws, the importance of data classification cannot be overstated. The Lepide Data Security Platform plays a crucial role in this process. It facilitates the discovery and classification of various types of data across a wide range of platforms, including both cloud-based and on-premise servers. Below are some of the main features/benefits that our Data Classification software provides.
- Sensitive Data Discovery – Pre-defined schemas can be used to locate unstructured sensitive data across all data repositories, on-premise or cloud-based, which can be aligned it with compliance mandates like HIPAA, SOX, PCI, GDPR, CCPA, and more.
- Incremental Scanning – Our solution scans various file formats like Word and text documents, PDF files, and Excel spreadsheets to discover sensitive data. Data can be classified incrementally during creation and modification, ensuring a fast, scalable, and reliable process.
- More context to classified data – Our software provides information about sensitive data location, access, and usage, enabling organizations to apply appropriate access controls.
- Real-time threat detection – Our software can automatically identify and respond to hazardous user behavior in real-time, and provide reports and alerts on how users interact with sensitive/regulated data.
- Reduction in False Positives – The Lepide software leverages proximity scanning to discover patterns that add context, ensuring accurate predictions of sensitive data and avoiding false positives.
- Better Access Governance – Our data classification solution enables companies to manage access to sensitive information, and restrict excessive permissions, for better data access governance (DAG).
- Prioritization Based on Risk – Our solution assesses the level of risk associated with content, categorizes it, and assigns scores. Identifying important data enables organizations to concentrate on it and implement effective access control and activity monitoring.
If you’d like to see how the Lepide Data Security Platform can help you discover and classify your sensitive data, schedule a demo with one of our engineers.


 Group Policy Examples and Settings for Effective Administration
Group Policy Examples and Settings for Effective Administration 15 Most Common Types of Cyber Attack and How to Prevent Them
15 Most Common Types of Cyber Attack and How to Prevent Them Why the AD Account Keeps Getting Locked Out Frequently and How to Resolve It
Why the AD Account Keeps Getting Locked Out Frequently and How to Resolve It
